
Michael Taylor
Senior Software Engineer supporting CoreAI at @microsoft
Highlights
Six Years of MLMB: Building a March Madness Prediction System from Scratch
Published Apr 10, 2026
Share
Project: MLMB: Machine Learning March Bracketology
Six years ago, during a pandemic lockdown in my senior year at UConn, I built a scrappy web app to predict March Madness games. What started as a self-imposed one-week sprint has since evolved into a full-stack AI prediction platform with three major rewrites, two back-to-back bracket challenge victories, and a bracket that climbed to the 99.8th percentile on ESPN this year. This is the story of MLMB.
How It Started: Becoming a UConn Basketball Fan
I have to credit my interest in college basketball to the 2018–2019 UConn Women’s basketball team. That year, my sophomore year, students were offered free tickets to the second round of the NCAA tournament on campus. Our women’s program was playing the University of Buffalo, and my friends and I decided to go. We watched UConn win, and we kept following the team as they advanced all the way to the Final Four. That season ended in a heartbreaking loss to Notre Dame in the semis, which we watched on TV together.
I had never really been interested in following sports before that, but that tournament run pulled me in. I started to appreciate the legacy that the UConn women’s program had built, and it became a genuine source of school pride.
The following year, my junior year, I was following both the men’s and women’s programs. The 2019–2020 season was the school’s final year in the American Athletic Conference, and it was a heavy year. The women’s program was highly ranked but clearly struggling. That was also the year of the tragedy involving Kobe and Gigi Bryant, who had famously visited Storrs to watch a game the previous season because Gigi dreamed of playing for UConn. Following their deaths in January 2020, the team hosted a moving tribute, draping a personalized No. 2 jersey with flowers on the bench. On the men’s side, I watched the team continue its rebuild, grinding out games as underdogs. Unfortunately, COVID cut the season short before March Madness ever happened.
V1: One Week, Built from Scratch (2021)
Then came my senior year. I didn’t have many classes left because I had front-loaded most of my coursework through my first three years and summer sessions, and I had already received my offer to join Microsoft back in October, before I even sat for my first set of senior-year midterms. So I had a lot of free time, and unfortunately, a lockdown to spend it in.
That summer, I had completed Google Cloud’s “NCAA March Madness: Bracketology” course, which walked through using BigQuery and ML to predict tournament outcomes. It planted the seed for what came next.

By December 2020, I was scripting together datasets and feature engineering to train machine learning models in a Jupyter notebook. Nothing fancy, just a way to predict basketball games using what I’d learned in my junior-year ML course and that Google Cloud course.
Meanwhile, I was watching a lot of UConn basketball. It was our first year back in the Big East. The men’s program was ranked again after a couple of years of rebuilding under Dan Hurley, who had been hired toward the end of my freshman year. When the men’s team made the NCAA tournament again for the first time in several years, the excitement was real, and the program was clearly back on the map.
When Selection Sunday hit, something clicked. I spent the entire week between the bracket announcement and the submission deadline building the first version of MLMB, all day and all night. I named it MLMB because the acronym had a ring to it. At the time it stood for “Machine Learning on Men’s Basketball,” since that was the only dataset freely available. That changed years later when women’s basketball data was also made available for free, and I rebranded it to “Machine Learning March Bracketology,” keeping the same acronym while broadening the scope.
The ML pipeline itself was straightforward but functional: I scraped game-by-game box score data, computed rolling averages of team statistics as features, and trained scikit-learn classifiers to predict game outcomes as a binary classification (win/loss). The features were things like field goal percentage, rebounds, turnovers, and pace, all aggregated over a team’s recent games to capture current form. I serialized the trained models with joblib so they could be loaded at inference time.
For the frontend, I knew just enough Angular to piece together a basic UI. On the backend, I deployed a Flask app on Heroku that loaded the serialized models and exposed prediction endpoints. Looking back, I knew just enough about each technology to cobble it all together, but I definitely did not know the best practices. I didn’t understand proper REST API design, so I was essentially passing raw parameters and returning unstructured responses. There’s a lot I would do differently if I rebuilt that specific version today. You can see the archived code here: MLMB-Heroku on GitHub.
The sheer scope of what I pulled off in a single week still impresses me when I look back on it. End to end, I had to scrape and clean historical game data, engineer features from raw box scores, train and evaluate ML models, serialize them for production use, build and deploy a Flask API on Heroku, scrape team logos for every NCAA D1 program, and wire up an Angular frontend to call the API and display results with team branding. I spent an entire night figuring out how to set up a sticky header and footer. I even had to troubleshoot Heroku’s free-tier memory limits. Loading multiple serialized scikit-learn models into a single dyno pushed me past the threshold, so I had to trim the model artifacts and optimize memory usage to stay within the free tier.
If I had to compare that week to anything, the closest analogy would be a hackathon, except there was no event, no prize, and no team. This was purely for my own interest and my own drive. I imposed the deadlines on myself, which is funny in retrospect, because nothing would have happened if I didn’t deliver. There was nothing to lose.
V1 Tech Stack: Python, scikit-learn, Flask, Heroku, Angular, BeautifulSoup (web scraping)
I pieced it all together just in time and submitted my bracket the morning of the first game. In the UI, you could add a row for two teams, and it would show the predicted outcome with each school’s logo. A lot of different pieces seamlessly connected and delivered as a web app my friends and I could use on the go.
The Texas Upset
One prediction I will never forget from that very first version: Abilene Christian (14 seed) over Texas (3 seed), one of the biggest upsets of the 2021 NCAA tournament. MLMB called it. I bet on it against my friends and won big.
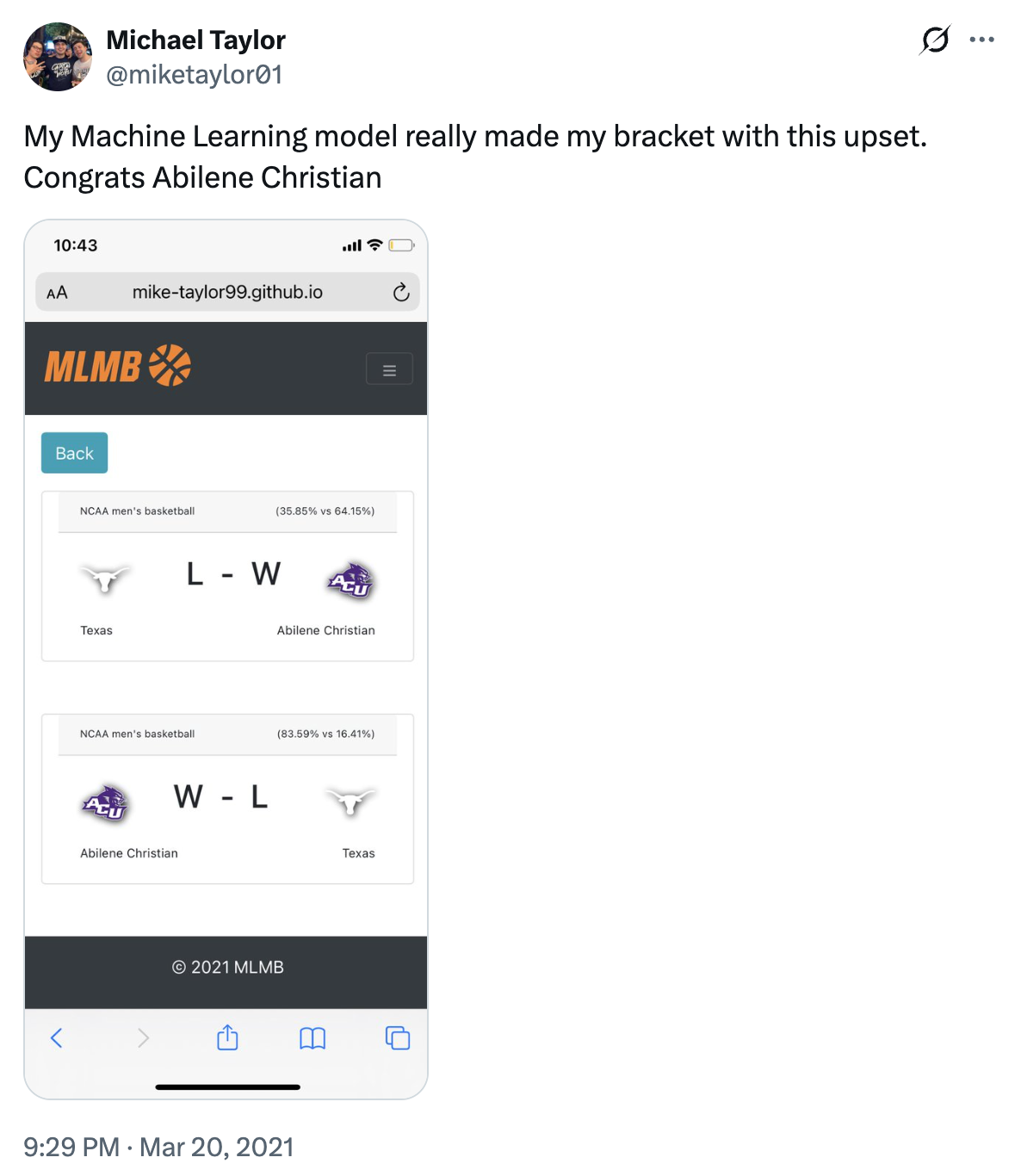
Seeing that kind of validation in a system I had built from scratch only deepened my obsession with the project and the sport. I remember Texas head coach Shaka Smart leaving the university for Marquette just days after losing that game. Year one of this passion project was a success, and I carried it forward after graduating and joining Microsoft as a full-time software engineer.
V2: Going Professional (2022–2024)
Working as a software engineer at Microsoft in AI Platform, I learned significantly more about the craft of software engineering and deploying ML models at scale. Naturally, I rebuilt the system from the ground up.
The biggest problem with V1 was that the model’s feature inputs were static, baked into the deployment at whatever point in time I last uploaded the serialized models. If a team went on a 10-game winning streak mid-season, the predictions wouldn’t reflect that until I manually retrained and redeployed. V2 solved this by decoupling the model weights from the team statistics. I wrote a data pipeline that scraped the latest stats for every D1 team and pushed them to Azure Blob Storage as structured data files. At inference time, the API would pull a team’s current stats from blob, construct the feature vector on the fly, and feed it into the model. This meant predictions always reflected a team’s most recent performance without any manual intervention.
For model hosting, I moved from a Flask app on Heroku to Azure Machine Learning (AML) online endpoints. Instead of loading serialized joblib files into a web server, I registered the trained models as AML assets and deployed them behind managed endpoints with built-in scaling, monitoring, and versioning. This was the same infrastructure that sister teams in my AI Platform organization were building and delivering to customers, so it was a natural fit and gave me hands-on experience with the technology I was adjacent to at work.
On the frontend, I rebuilt the UI from scratch in React and TypeScript, replacing the Angular app. V2 was also when I introduced women’s basketball predictions, now that the dataset had become freely available, which meant training and deploying separate model ensembles for men’s and women’s games.
V2 Tech Stack: Python, scikit-learn, React + TypeScript, Azure Machine Learning (AML online endpoints), Azure Blob Storage
Winning the AI Platform Bracket Challenge
During those years at AI Platform, our President would host an org-wide March Madness bracket competition. In both 2023 and 2024, I won, and coincidentally, UConn was the national champion both of those years.
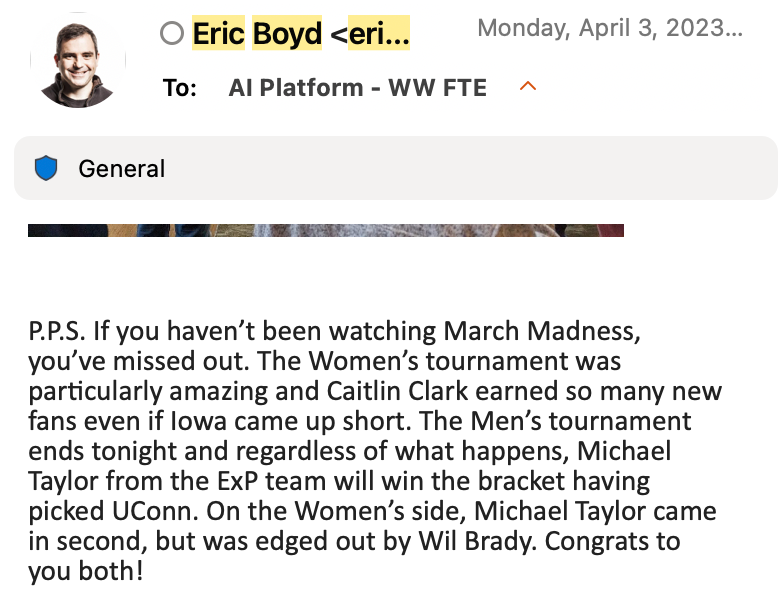
I think people assumed I just got lucky because I picked my own school to win. But I had an entire ML system engineered specifically for this purpose. The 2024 win really proves the point: nearly everyone in the pool picked UConn that year since they were the defending champions. I still won, which means I was getting more of the other picks correct, a direct credit to the models.
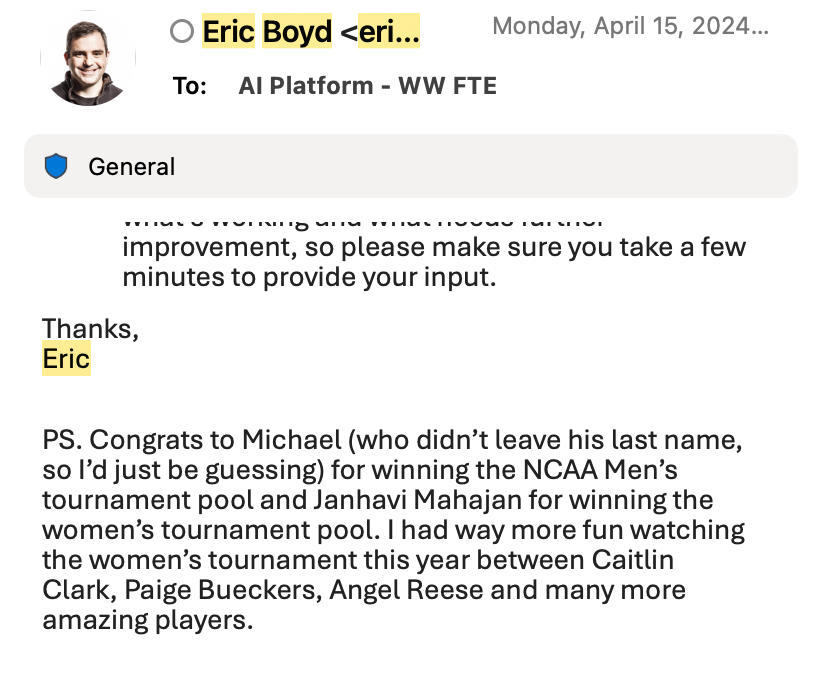
I still laugh at the announcement email because Eric had to guess which “Michael” won since I didn’t include my last name. I had named my bracket after mlmb.io, which linked straight to my GitHub and my full identity at the time, but I guess the connection flew under the radar! It’s pretty ironic, too, considering that version of MLMB made good use of the Azure AI technologies his own organization was shipping.
V3: The Full Platform (2025–2026)
Most recently, I rebuilt MLMB from the bottom up as a true predictions platform. V2 was a significant step up from V1, but it was still essentially a model-serving API with a React frontend bolted on. V3 was my chance to architect a real system and think about data engineering, availability, storage tiering, idempotency, and user experience holistically.
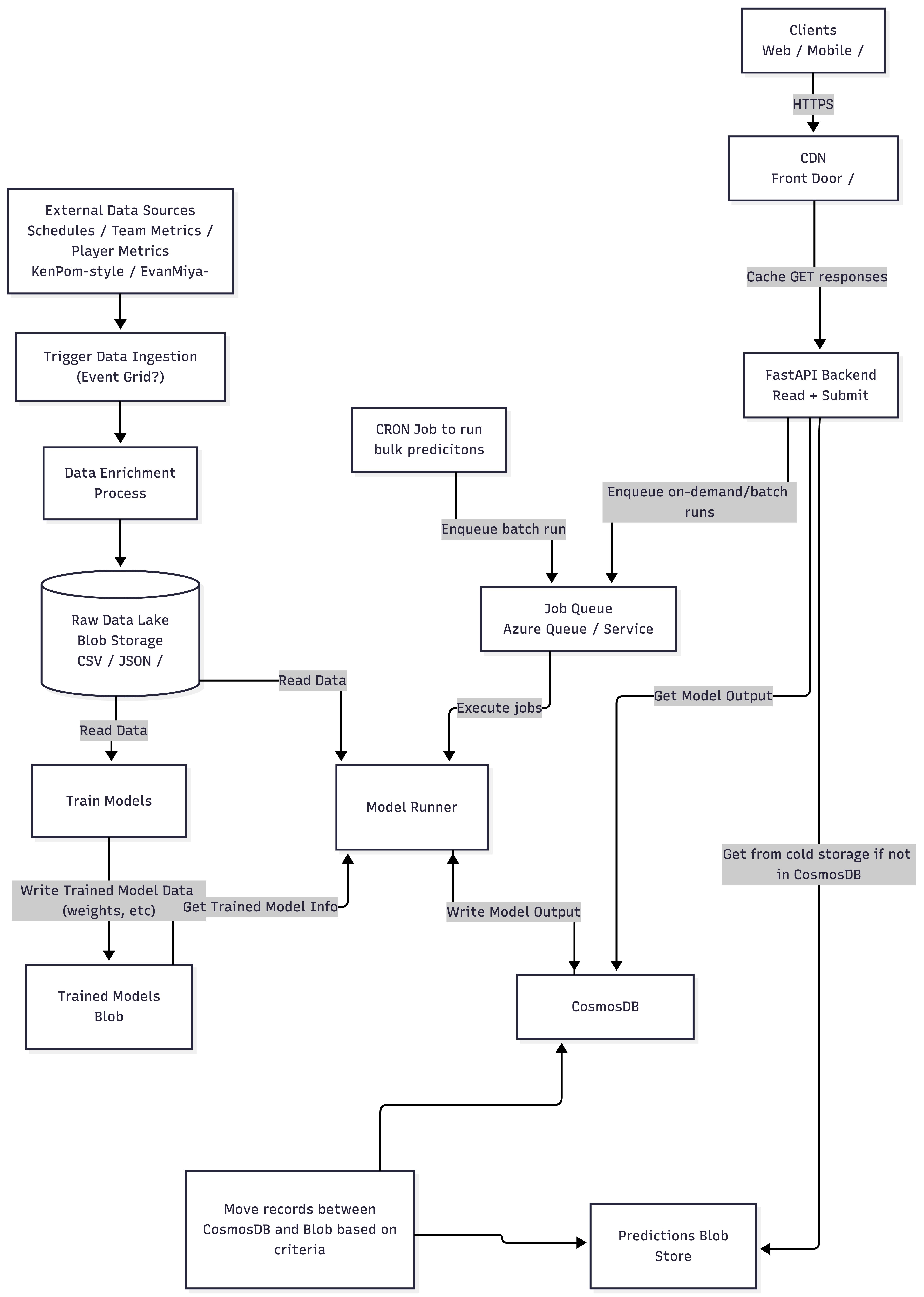
System Architecture
The architecture has several distinct layers:
Data Ingestion & Enrichment. External data sources (team schedules, box scores, advanced metrics) are ingested via an event-driven pipeline. Raw data lands in Azure Blob Storage as a data lake (CSV/JSON), where an enrichment process cleans, normalizes, and prepares it for both model training and real-time inference.
Model Training & Serving. Training jobs read from the data lake and write trained model artifacts (weights, scalers, metadata) back to blob storage. At inference time, a Model Runner service pulls the latest model artifacts, constructs feature vectors from current team stats, and executes predictions. Rather than hosting models behind expensive always-on managed endpoints (as in V2), the Model Runner runs as a job-based service that can be triggered on-demand or via CRON for bulk prediction runs, which significantly reduced cost.
Job Queue. Prediction requests, whether from user interactions on the frontend or from scheduled batch runs, are enqueued onto an Azure Queue. The Model Runner pulls from this queue, executes the prediction, and writes the result to Cosmos DB. This decoupled the API response time from model inference latency and gave me a natural mechanism for batch processing.
Storage Tiering. Cosmos DB serves as the hot store for predictions, user data, analyses, and brackets. For cost management, a background process moves older prediction records from Cosmos DB to blob cold storage based on age and access patterns. The API is smart enough to check Cosmos first and fall back to cold storage for historical lookups.
API & CDN. The FastAPI backend handles reads and writes, with Azure Front Door sitting in front as a CDN to cache GET responses and reduce latency for repeated lookups (e.g., the same matchup prediction being viewed by multiple users).
Key Features
- Authentication (OAuth): Sign in with a Microsoft or GitHub account via OAuth to track your prediction history across sessions
- Idempotent predictions: Every prediction is keyed by a deterministic hash of its inputs (team A, team B, span, home/away configuration). If the result already exists in Cosmos DB, the API returns it immediately without re-running inference. This guarantees consistency and eliminates redundant compute
- Interactive bracket grid: Users can fill out a full 64-team tournament bracket and share it, something I had envisioned since V1 but never had the architecture to support
- AI-powered analyses: This was the flagship feature of V3. Instead of manually running 6+ predictions per matchup with different span and home/away combinations, which is what I used to do to fill out my bracket, analyses bundle all model runs together automatically. On top of the raw ML outputs, an LLM generates a sports-analyst-style breakdown of the matchup, contextualizing the probabilities with each team’s recent form, strengths, and weaknesses. Analyses are also idempotent, keyed by matchup and tournament
- Built on Microsoft Foundry Agent Platform: The LLM analysis runs on the agent platform that my current team at Microsoft builds. I defined a specialized agent with a system prompt that instructs it to reason like a sports analyst, consuming the structured prediction data and team stats as context. It was genuinely gratifying to use my own team’s product in my own passion project
V3 Tech Stack: Python, FastAPI, React + TypeScript, Azure Cosmos DB, Azure Blob Storage, Azure Queue, Azure Front Door (CDN), Microsoft Foundry Agent Platform, OAuth (Microsoft + GitHub)
2026: A Run to the 99.8th Percentile
This year was special. Before the national championship game, the bracket I filled out using MLMB climbed to the 99.8th percentile of all brackets on ESPN, rank 56,106 out of millions. You can view my full 2026 men’s bracket on MLMB.
I correctly picked 3 of the 4 Final Four teams on the men’s side and nailed both teams in the national championship game: UConn vs. Michigan. Obviously, I picked UConn to win. I would never pick against my own team in a title game.
Michigan won. I was there in person.
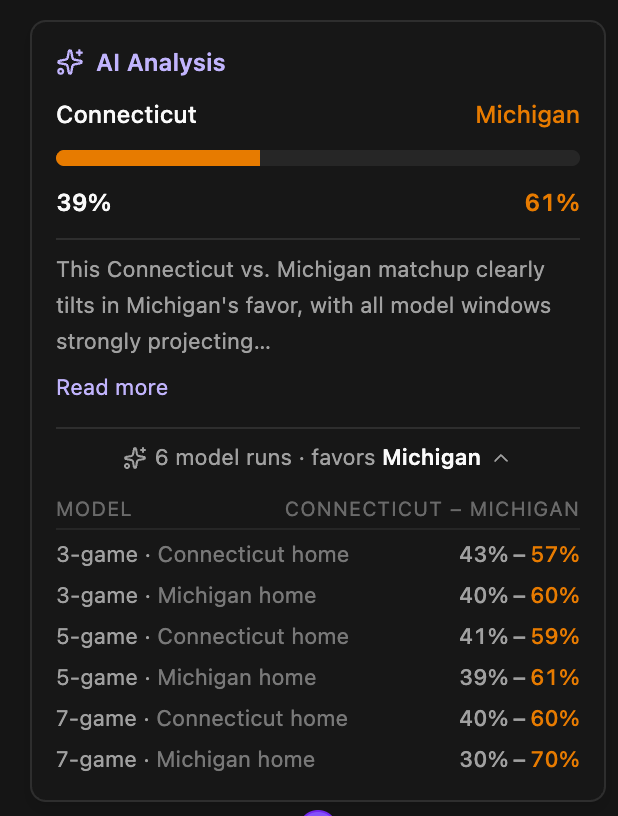
MLMB actually had Michigan winning across all six model configurations, with probabilities ranging from 57% to 70% in Michigan’s favor. I should have listened to my own system. That would have likely pushed me into the 99.9th percentile. Instead, I dropped to 94.1% after UConn’s loss.
In my defense: UConn was 6-0 all-time in national championship games, and had not lost a tournament game from the Sweet 16 onward since 2011.
A Spoiled Basketball Fan
I am incredibly proud of UConn and fully aware of how spoiled I’ve been as a fan. UConn men’s and women’s basketball are absolute dynasties. Over the last four seasons, I’ve attended four Final Fours: three on the men’s side (2023, 2024, 2026) and the 2025 women’s national championship, where I watched UConn win.
This year’s loss to Michigan was the first championship loss I’ve witnessed in person, and honestly, it was a painful first but probably long overdue given the historic run the program has been on. I couldn’t bring myself to pick against them, even when my own models told me to.
That tension is part of what makes MLMB so personal to me. It sits right at the intersection of fandom and engineering. Over six years, it has helped me and my friends win bracket challenges consistently, and this year’s run into the 99.8th percentile felt like the clearest validation yet.
Chasing the Perfect Bracket
At its core, MLMB has always been my attempt at cracking the perfect bracket. The odds are absurd: a 64-team single-elimination bracket has $2^{63}$ possible outcomes, roughly 9.2 quintillion unique combinations. Even if you know basketball, estimates from mathematicians put the odds of perfection at around 1 in 120 billion once you account for seed-matchup probabilities and historical upset rates.
In 2014, Warren Buffett and Quicken Loans put up a $1 billion prize for anyone who could fill out a perfect bracket. Nobody came close. No one ever has. The longest verified streak of correct picks to start a tournament is around 50 games out of 63.
I have never seriously expected to get there. But the question that drives this project is: how close can a machine learning system get? Every version of MLMB has been an iteration on that question: better features, better models, better data pipelines, better architecture, all in pursuit of squeezing out another percentage point of accuracy. Getting to the 99.8th percentile this year felt like real, measurable progress toward an answer, even if the perfect bracket remains a statistical impossibility.
But chasing perfection and winning your bracket pool are actually two different problems.
The Value Pick
Here’s the thing about bracket pools: you don’t win by picking the most likely outcome for every game. The all-chalk bracket (every favorite wins) is the single most probable bracket, but it’s also the most common one in the pool, so it almost never wins. To actually climb the leaderboard, you need to pick correctly where everyone else picks wrong.
This is the concept of the “value pick,” explained well in this video by HoopVision68. The idea is simple: if 80% of the public is on Team A but your model says the game is closer to 55/45, picking Team B gives you a massive scoring edge if they win, because almost nobody else in the pool has them advancing. You’re not maximizing accuracy, you’re maximizing expected value against the field.
This is exactly where MLMB shines. The model doesn’t care about seeds, brand names, or media narratives. It looks at rolling statistics, defensive matchup data, and ensemble-averaged probabilities. When the model’s output diverges from public consensus, that’s a signal. The Abilene Christian pick in 2021 was a value pick. The decisions that pushed me to the 99.8th percentile in 2026 were value picks. Winning the AI Platform bracket challenge two years in a row wasn’t luck; it was the model finding edges that the field missed.
The ML System
If you want the full technical deep dive on the current prediction engine, I wrote that separately here: Incorporating Opponent Defensive Statistics into NCAA Basketball Game Outcome Prediction: An Ensemble Machine Learning Approach. The short version is this:
The system trains an ensemble of 7 classification models: Logistic Regression, SVM, Random Forest, Gradient Boosting, MLP, XGBoost, and LightGBM. They run inside standardized scikit-learn pipelines with StandardScaler, and each model is independently hyperparameter-tuned via GridSearchCV. The final production model is a soft-voting VotingClassifier that averages the predicted probabilities across all 7 models.
The feature set comprises 59 raw statistics per team (35 offensive + 24 defensive opponent stats), each transformed into 3 moving average representations (simple, cumulative, and exponential), yielding 355 engineered features per game row. Models are trained separately for men’s and women’s basketball. The men’s ensemble uses a 5-game rolling window, while the women’s uses a 7-game window, selected through cross-validated span comparison.
The production ensembles achieve 69.94% accuracy on men’s basketball and 74.23% accuracy on women’s basketball on held-out test data. For a binary classification task in a domain with significant inherent randomness (single-elimination games between D1 programs), these numbers represent meaningful signal above the 50% baseline.
By the Numbers (2026 Season)
During March Madness, mlmb.io saw over 80 unique users. Across the full 2026 season, the platform handled meaningful backend throughput:
| Metric | Count |
|---|---|
| Total predictions | 70,615 |
| User-tracked predictions | 25,877 |
| AI analyses generated | 312 |
To put those numbers in context: 70,615 predictions means the ensemble was invoked over 70K times this season, with each request constructing a feature vector from live team stats, running inference across 7 models, averaging probabilities, and writing the result to Cosmos DB. The 25,877 user-tracked predictions represent authenticated activity whose results are persisted and queryable across sessions. And the 312 AI analyses each involved 6 model runs plus an LLM agent call through the Microsoft Foundry Agent Platform, with the full result cached for subsequent lookups.
Acknowledgments
This project has been a solo effort in many ways, but several people have made meaningful contributions over the years:
-
Sam Kasbawala: Helped set up the original feature engineering scripts back in December 2020. This was the foundation for training the ML models, and much of the code he wrote all the way back then is still in production today for computing training and real-time statistics.
-
Brandon Mino: My go-to software architecture consultant. A close friend, UConn basketball diehard, and fellow software engineer. Brandon and I are constantly bouncing ideas off each other, and he’s helped me think through how to architect the system and expand its capabilities at every stage.
-
Finn Navin: One of the best UI/UX engineers I know, and a fellow software engineer at Microsoft. Finn has a genuine craft for building web apps, and I’m extremely grateful for all the help he has provided across the several versions of MLMB’s UI. Shoutout to him for hopping on a call with me while riding the NYC subway when I was trying to piece together V2 of the frontend.
-
Taaj Cheema: Another UConn basketball diehard. Has attended multiple Final Fours and championship games with me, and has provided analytical insights that helped improve the models.
The Evolution at a Glance
| Layer | V1 (2021) | V2 (2022–2024) | V3 (2025–2026) |
|---|---|---|---|
| Frontend | Angular | React + TypeScript | React + TypeScript |
| API / Backend | Flask | Flask | FastAPI |
| ML Serving | Serialized models loaded in-process | AML online endpoints | Self-hosted Model Runner + job queue |
| Prediction Execution | Synchronous request/response | Managed endpoint inference | Queued jobs + idempotent cache |
| Data Pipeline | Static manual uploads | Automated scrape to Blob | Event-driven ingestion + enrichment |
| Persistence | None | Blob-backed team stats | Cosmos DB + Blob cold storage |
| Cloud Footprint | Heroku free tier | Azure Blob + AML endpoints | Azure Front Door + Queue + Blob + Cosmos DB |
| Auth / Identity | None | None | OAuth (Microsoft + GitHub) |
| AI / LLM Layer | N/A | N/A | Microsoft Foundry Agent Platform |
| Product Surface | Men’s matchup predictions | Men’s + Women’s matchup predictions | Men’s + Women’s predictions + analyses + brackets + accounts |
What’s Next
MLMB has gone from a scrappy one-week build to a system that processes tens of thousands of predictions per season, and I have no plans of stopping. Some things I’m thinking about for V4 and beyond:
- Player-level features: The current models operate entirely on team-level aggregated statistics. Incorporating individual player data, such as minutes played, injury status, and matchup-specific performance, could meaningfully improve prediction quality, especially for tournament games where rotations tighten.
- Live in-game predictions: Right now MLMB is a pre-game tool. Extending it to update win probabilities as a game progresses using live box score data would be a compelling real-time application.
- Expanding beyond basketball: The core architecture, including data ingestion, feature engineering, ensemble ML, job queueing, and idempotent prediction storage, is sport-agnostic. College football or soccer would be natural next targets.
Six years in, MLMB is still the project I’m most proud of. It sits at the intersection of everything I care about: software engineering, machine learning, AI, and UConn basketball. And it keeps getting better.